NVIDIA GEFORCE RTX 2080 TI CARTE GRAPHIQUE |, NVIDIA RTX 2080 TI, 2080, & 2070 Spécifications, prix, date de sortie | GAMERSNEXUS – Gaming PC Builds et Benchmarks matériels
2080 TI Date de sortie
Cependant, l’aspect le plus important de cette nouvelle est que l’interconnexion cohérente du cache de NVIDIA, NVLink, arrivera sur les cartes de consommation. Les cartes GeForce GTX implémenteront SLI sur NVLink, avec 2 canaux NVLink exécutés entre chaque carte. À une bande passante combinée de 50 Go / secon. Ceci est au-dessus des autres avantages de la fonctionnalité de NVLink, en particulier la cohérence du cache. Et tout cela arrive à un moment important, car les exigences de bande passante inter-GPU continuent de monter à chaque génération.
NVIDIA GEFORCE RTX 2080 TI CARTE GRAPHIQUE
MODDED GEFORCE RTX 2080 TI prend en charge 22 Go de mémoire GDDR6
TECLAB brise la barrière d’horloge GPU de 3 GHz avec GeForce RTX 2080 TI
Les rumeurs de Nvidia auraient retiré GeForce RTX 2080 (TI / Super) et GeForce RTX 2070 (Super) Cartes graphiques bientôt
MSI OutS GeForce RTX 2080 TI GAMING Z avec 16 Gbps GDDR6 MÉMOIRE
Nvidia annonce GeForce RTX 2080 TI «Cyberpunk 2077 Edition»
Asus montre GeForce RTX 2080 Ti Rog Strix White Edition
Gigabyte lance la boîte de jeu AORUS avec RTX 2080 TI
GALAX GEFORCE RTX 2080 TI HOF 10e anniversaire Edition repérée
MSI RTX 2080 TI Lightning 10th Anniversary Edition illustré
MSI taquine GeForce RTX 2080 TI Lightning 10th Anniversary Edition
(PR) MSI annonce GeForce RTX 2080 ti Lightning Z
Evga Geforce RTX 2080 Ti Kingpin Edition est un hybride
MSI GeForce RTX 2080 ti Lightning illustré
Asus présente ROG GEFORCE RTX 2080 TI Matrice
Geforce coloré RTX 2080 TI IGAME KUDAN SMILES POUR CAME
MSI taquine en fibre de carbone geforce rtx 2080 ti Lightning z
ZOTAC GEFORCE RTX 2080 TI ARCTICSTorm pour faire ses débuts au CES 2019
MSI GeForce RTX 2080 TI Lightning Z PCB illustré
Colorful lance GEFORCE RTX 2080 (TI) RNG Edition avec LCD en pleine couleur
(PR) Inno3d annonce la série GeForce RTX Ichill Frostbite
Evga taquine geforce rtx 2080 ti kingpin
Gigaoctet préparant le geforce rtx 2080 ti aorus turbo
Nvidia Bundles Battlefield V avec GeForce RTX gratuitement
(PR) Manli annonce GeForce RTX 2080 TI & 2070 avec un ventilateur de soufflant
Nouveau rapport de carte n ° 21: l’édition RTX RVB
Inno3d transforme la carte GeForce RTX en arbre de Noël géant RVB
MSI annonce GeForce RTX 2080 (TI) Sea Hawk (EK) X Series
Gigabyte taquine GEFORCE RTX 2080 (TI) AORUS Graphics Carte
Nvidia Geforce RTX 2080 TI & RTX 2080 Revue Roundup
TechPowerp explique la différence entre les variantes de Turing A et non A GPU
NVIDIA GEFORCE RTX 2080 TI ET RTX 2080 Performance «officielle» dévoilée
Les nouvelles fonctionnalités de l’architecture Nvidia Turing
NVIDIA change GEFORCE RTX 2080 Examen de la date du 19 septembre
Nvidia Geforce RTX 2080 Avis en ligne le 17 septembre
EVGA dévoile des modèles Hydro Copper et Hybrid GeForce RTX
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 Geforce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Centre de données / Tesla
- Tegra
- Ptique de travail / quadro
- GeForce MX
- Titan RTX
- Geforce rtx 2080 ti
- Geforce rtx 2080 super
- Geforce rtx 2080
- Geforce rtx 2070 super
- Geforce rtx 2070
- Geforce rtx 2060 super
- Geforce rtx 2060 12 Go
- Geforce rtx 2060
- GeForce MX250
- Empilement 3D
- Accessoires
- Annonces
- Pomme
- BRAS
- Intelligence artificielle
- Industrie automobile
- Repères
- Entreprise et marchés
- Graphiques chinois
- Concepts
- Connectivité
- Création de contenu
- Technologie de refroidissement
- Crypto-monnaie
- Projets personnalisés
- Offres
- Affichages et moniteurs
- Événements
- GPU et enclos externes
- Avis externes
- Overclocking extrême
- Résultats financiers
- Fonderie
- Bundles et offres de jeu
- Exigences de jeu
- Streaming de jeu
- Jeux
- Consoles de jeu
- Matériel de jeu
- Graphique
- API graphiques
- Interviews
- Linux
- Technologie de mémoire
- Mini / SFF / Nuc PCS
- Appareils mobiles
- Modding
- Cartes mères
- Des cahiers
- Brevets et recherche
- Cas PC
- PCI Express
- Personnes
- Alimentation électrique
- Systèmes prédéfinis
- RISC-V
- Sécurité
- Logiciels et moteurs
- Stockage
- Super résolution
- Supercomputing (HPC)
- Codage vidéo
- Histoires virales
- Réalité virtuelle
- Eau froide
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000 Mobile
- 2022 Radeon 7000
- 2021 Radeon 6000 Mobile
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000 Mobile
- 2017 Radeon 500
- Radeon 500 mobile 2017
- 2016 Radeon 400
- Radeon 400 mobile 2016
- 2015 Radeon 300
- Radeon 300 mobile 2015
- 2014 Radeon 200 Mobile
- 2013 Radeon 200
- Instinct de Radeon
- Radeon Pro
- Blockchain Calcul
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 Geforce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Centre de données / Tesla
- Tegra
- Ptique de travail / quadro
- GeForce MX
- 2025 arc druid tba
- 2024 arc céleste tba
- 2023 Arc Battlemage TBA
- 2022 ALCHEMIST ARC
- 2022 Intel Data Center HPC TBA
- 2021 Intel Data Center HP TBA
- 2020 Intel Xe-lp
- Arc pro
2080 TI Date de sortie
NVIDIA RTX 2080 TI, 2080, & 2070 Spécifications, prix, date de sortie
Par Steve Burke Publié le 20 août 2018 à 15h00

Mise à jour: Ajout d’une correction pour les numéros de noyau SM / CUDA, maintenant que les détails complets ont été divulgués.
Nvidia a annoncé ses nouvelles cartes vidéo Turing pour le jeu aujourd’hui, y compris le RTX 2080 TI, RTX 2080 et RTX 2070. Les cartes avancent avec une architecture Volta améliorée mais familière, avec quelques modifications du SMS et de la mémoire. Les nouveaux Ship RTX 2080 et 2080 avec les cartes de référence d’abord et les cartes partenaires en grande partie en même temps (avec des modèles plus avancés à venir 1 mois plus tard), Selon le partenaire qu’il s’agit. Les partenaires du conseil d’administration n’ont reçu des prix ni même des noms de cartes avant le même moment que les médias, alors attendez-vous à des retards dans les solutions personnalisées. Notez que nous entendions à l’origine une latence de 1 à 3 mois sur les cartes partenaires, mais cela semble être uniquement pour des modèles avancés qui entrent dans la production. La plupart des modèles tri-fans devraient être disponibles à la même date.
Un autre point de considération majeur est la décision de Nvidia d’utiliser une carte de référence à double axiale, éliminant une grande partie de la valeur des cartes partenaires à bas de gamme. S’éloigner des cartes de référence de soufflerie et vers des cartes à double-fan aura le plus d’impact sur les partenaires du conseil d’administration, ce qui pourrait conduire à une analyse lente de Nvidia élargissant ses ventes directes à consommation et les partenaires de contournement. Le RTX 2080 TI sera au prix de 1200 $ et sera lancé le 20 septembre, avec le 2080 à 800 $ (et le 20 septembre) et le 2070 à 600 $ (date de sortie TBD).
Nvidia RTX 2080 TI & 2080 Spécifications
L’une des plus grandes erreurs que les gens commettent lors de la comparaison de nouveaux GPU est de parler du «Core Count.”Ceci est erroné pour plusieurs raisons, dont l’une est que les performances du cœur-pour-core ne sont pas des architectures croisées identiques. De Kepler à Pascal, il y a eu des gains à plus de 30% pour l’efficacité globale de performance par watt, et le simple fait de faire une comparaison linéaire entre les comptes de base ne s’adapte pas. De plus, les noyaux Cuda ne sont pas vraiment noyaux, de toute façon: ce sont des unités à virgule flottante. Un SM serait plus similaire à un noyau par des définitions standard, qui appellent à un noyau qui sera capable de récupérer et de décoder les instructions, de les exécuter, de lire et d’écrire des données vers et depuis les registres et le cache, et calculer les résultats. Les unités à virgule flottante de Nvidia peuvent calculer les résultats, mais ne peuvent pas faire beaucoup d’autres choses.
Le but de dire tout cela est qu’un pascal strict vs. La comparaison du cœur de Turing doit tenir compte des différences architecturales qui pourraient modifier la façon dont un «noyau» fonctionne pour commencer. Les gens sont tombés dans le même piège la dernière fois.
Nvidia RTX 2080 TI, 2080 et 2070 Founders Edition Specs
La nouvelle RTX 2080 TI de Nvidia héberge 4352 unités de points flottants, avec l’hébergement RTX 2080 non-TI 2944 FPUS. Nvidia colle à 64 FPU par multiprocesseur en streaming, qui mettrait le 2080 TI à 68 SMS, avec le 2080 à 46 SMS. Nvidia a retravaillé l’architecture SM pour ce GPU, nous ne sommes donc pas positifs sur tous les plus beaux détails.
Les nouveaux GPU se déplacent également vers GDDR6, un changement attendu. À l’heure actuelle, GDDR6 exécute environ 20% de coût de bom plus élevé que GDDR5, mais ce coût baissera avec le temps. GDDR6 permet un débit minimal de 14 Gbitps par broche sur les RTX 2080 et 2080 Ti, un coup de pouce remarquable par rapport aux 8 Gops et 10 Gops sur les générations précédentes. GDDR6 peut également pousser jusqu’à 16 Gops par broche, mais il n’y a pas de promesse immédiate de cela pour les nouveaux GPU. Nous ne sommes pas encore sûrs de l’impact de synchronisation de la mémoire de GDDR6. Le 2080 Ti accueillera 11 Go de GDDR6 sur un bus mémoire 352 bits, avec une bande passante mémoire dans le quartier de 620 Go / s. Le RTX 2080 hébergera 8 Go de GDDR6 sur une interface de 256 bits et autorise donc la bande passante de mémoire de 448 Go / s.
| RTX 2080 TI | RTX 2080 | RTX 2070 | |
| FP32 fpus (“Cuda cores”) | 4352 | 2944 | 2304 |
| Streaming multiprocesseurs | 68 | 46 | 36 |
| Horloge de base / horloge de boost | 1350/1545 FE: 1635 MHz | 1515/1710 FE: 1800 MHz | 1410/1620 FE: 1710 MHz |
| Interface de mémoire | 352 bits | 256 bits | 256 bits |
| Capacité mémoire | 11 Go | 8 Go | 8 Go |
| Vitesse GDDR6 | 14 Gbit / s | 14 Gbit / s | 14 Gbit / s |
| Bande passante de mémoire | 616 Go / s | 448 Go / s | 448 Go / s |
| Sli | NvLink 2 voies | NvLink 2 voies | TBD |
| TDP | ~ 265 ~ 285W | ~ 250-260W | 175-185W |
| Prix | 1 200 $ Ou 1000 $ * | 800 $ Ou 700 $ * | 600 $ Ou 500 $ * |
| Date de sortie | Sept. 20, 2018 | Sept. 20, 2018 | TBD |
*Source des prix: le site Web de Nvidia. NOTE: Nous avons également entendu dire que les prix (peut-être pour les cartes non FE? Ou y a-t-il juste une mauvaise communication au sein de Nvidia?) pourrait également être de 500 $ pour le 1070, 700 $ pour le 2080 et 1000 $ pour le 2080 TI. Nous pensons que cela pourrait être Fe vs. Référence, mais cela pourrait également être une mauvaise communication par les équipes de Nvidia. Pas clair pour le moment.
Nvidia annonce la série GeForce RTX 20: RTX 2080 TI & 2080 le sept. 20e, RTX 2070 en octobre

Le Keynote de Nvidia GamesCom 2018 vient de se terminer, et comme beaucoup l’attendent depuis son annonce le mois dernier, Nvidia s’apprête à lancer sa prochaine génération de matériel GeForce. Annoncé lors de l’événement et en vente à partir du 20 septembre, la série GeForce RTX 20 de Nvidia, qui succède à la série Geforce GTX 10 actuelle propulsée par Pascal. Basé sur la nouvelle architecture GPU Turing de NVIDIA et construit sur le processus «FFN» de 12 nm de TSMC, NVIDIA a des objectifs élevés, cherchant à générer un changement de paradigme complet dans la façon dont les jeux sont rendus et comment les cartes vidéo PC sont évaluées. Le PDG Jensen Huang a appelé l’architecture GPU la plus importante de Turing Nvidia depuis l’architecture GPU Tesla de 2006 (G80 GPU), et du point de vue des fonctionnalités, il est clair qu’il ne surestime pas les choses.
Comme c’est traditionnellement le cas, les premières cartes de l’écurie Nvidia sont les cartes haut de gamme. Mais dans une pause plutôt importante dans la tradition, nous allons non seulement obtenir les cartes X80 et X70 au lancement, mais aussi la carte X80 TI. Ce qui signifie que le GeForce RTX 2080 Ti, RTX 2080 et RTX 2070 arrivera tous dans les rues à moins d’un mois les uns des autres. La pile de produits de Nvidia reste inchangée ici, donc RTX 2080 Ti reste leur carte phare, tandis que RTX 2080 est leur carte haut de gamme, puis RTX 2070 la carte légèrement moins chère pour attirer les passionnés sans se ruiner la banque.
Les trois cartes seront lancées au cours des deux prochains mois. Le premier sera le RTX 2080 TI et RTX 2080, qui lancera le 20 septembre . Le RTX 2080 TI commencera à 999 $ pour les cartes partenaires, tandis que le RTX 2080 commencera à 699 $. Pendant ce temps, le RTX 2070 sera lancé à un moment donné en octobre, avec des cartes partenaires à partir de 499 $. Sur une base historique, tous ces prix sont plus élevés que la dernière génération entre 120 $ et 300 $. Pendant ce temps, les cartes d’édition des fondateurs de qualité de référence de Nvidia sont à nouveau de retour, et celles-ci porteront une prime de 100 $ à 200 $ par rapport au prix de référence.
Malheureusement, Nvidia prend déjà des précommandes ici, donc les consommateurs sont essentiellement tenus de faire un «achat aveugle» s’ils veulent accrocher une carte à partir du premier lot. Nvidia a offert étonnamment peu d’informations sur les performances et nous suggérons d’attendre des critiques de tiers fidèles (I.e. nous), mais je dois admettre que je n’imagine pas qu’il y aura beaucoup de stock disponibles au moment où les critiques ont frappé les rues.
| Comparaison des spécifications de Nvidia GeForce | ||||||
| RTX 2080 TI | RTX 2080 | RTX 2070 | GTX 1080 | |||
| Cœurs cuda | 4352 | 2944 | 2304 | 2560 | ||
| Horloge de base | 1350 MHz | 1515 MHz | 1410mhz | 1607MHz | ||
| Sauter l’horloge | 1545 MHz | 1710mhz | 1620 MHz | 1733MHz | ||
| Horloge de mémoire | 14 Gops GDDR6 | 14 Gops GDDR6 | 14 Gops GDDR6 | 10 Gops GDDR5X | ||
| Largeur de bus mémoire | 352 bits | 256 bits | 256 bits | 256 bits | ||
| Vram | 11 Go | 8 Go | 8 Go | 8 Go | ||
| Perf de précision unique. | 13.4 tflops | dix.1 tflops | 7.5 tflops | 8.9 tflops | ||
| Tensor perf. | 440t OPS (INT4) | ? | ? | N / A | ||
| Ray Perf. | 10 gris / s | 8 gris / s | 6 gris / s | N / A | ||
| “RTX-OPS” | 78t | 60T | 45t | N / A | ||
| TDP | 250W | 215W | 175W | 180w | ||
| GPU | Gros turing | Turing sans nom | Turing sans nom | GP104 | ||
| Nombre de transistors | 18.6B | ? | ? | 7.2B | ||
| Architecture | Turing | Turing | Turing | Pascal | ||
| Processus de fabrication | Tsmc 12nm “ffn” | Tsmc 12nm “ffn” | Tsmc 12nm “ffn” | TSMC 16NM | ||
| Date de lancement | 20/09/2018 | 20/09/2018 | 10/2018 | 27/05/2016 | ||
| Prix de lancement | PDSF: 999 $ Fondateurs 1199 $ | PDSF: 699 $ Fondateurs 799 $ | PDSF: 499 $ Fondateurs 599 $ | PDSF: 599 $ Fondateurs 699 $ | ||
Architecture Turing de Nvidia: noyaux RT & Tensor
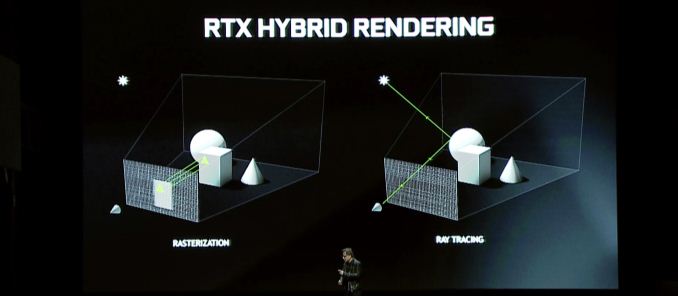
Alors qu’est-ce que Turing apporte à la table? La caractéristique de chapiteau à tous les niveaux est un rendu hybride, qui combine le traçage des rayons avec une rasterisation traditionnelle pour exploiter les forces des deux technologies. Cette annonce est essentiellement une continuation de l’annonce RTX de Nvidia de plus tôt cette année, donc si vous pensiez que cette annonce était un peu clairsemée, eh bien, voici le reste de l’histoire.
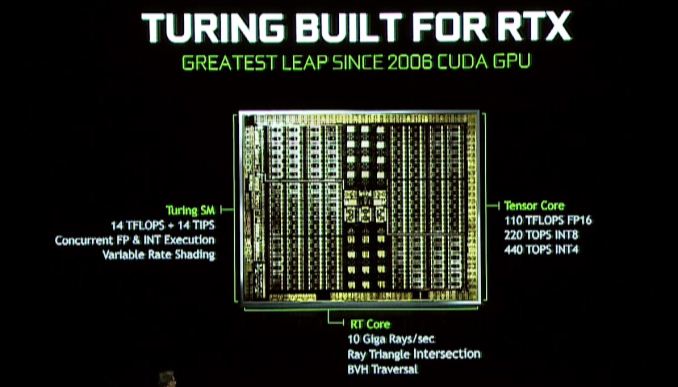
Le grand changement ici est que Nvidia va inclure encore plus de matériel de traçage de rayons avec Turing afin d’offrir une accélération plus rapide et plus efficace. Nouveau dans l’architecture Turing est ce que Nvidia appelle un noyau RT, dont les fondements ne sont pas entièrement informés pour le moment, mais servent de processeurs de traçage de rayons dédiés. Ces blocs de processeur accélèrent à la fois les contrôles d’intersection Ray-Triangle et la manipulation de la hiérarchie du volume de délimitation (BVH), ce dernier étant une structure de données très populaire pour stocker des objets pour le traçage des rayons.
Nvidia indique que la partie GeForce RTX la plus rapide peut proposer 10 milliards de rayons (Giga) par seconde, ce qui, par rapport à la Pascal non accélérée, est une amélioration de 25x des performances de traçage des rayons.
L’architecture Turing porte également les noyaux du tenseur de Volta, et en effet ceux-ci ont même été améliorés sur Volta. Les noyaux du tenseur sont un aspect important de plusieurs initiatives NVIDIA. En plus de l’accélérer le traçage des rayons lui-même, l’autre outil de Nvidia dans leur sac de tours de tours consiste à réduire la quantité de rayons requis dans une scène en utilisant le débroussage de l’IA pour nettoyer une image, ce que les noyaux de tenseur excellent. Bien sûr, ce n’est pas la seule caractéristique que les noyaux de tenseur sont destinés à – l’empire de réseautage AI / neuronal de Nvidia est presque construit sur eux – donc même si ce n’est pas un objectif principal pour la foule de Gamescom, cela confirme également que le matériel de réseautage neuronal le plus puissant de Nvidia arrivera à venir à une gamme plus large de GPU.
En regardant le rendu hybride en général, il est intéressant de noter que malgré ces accélérations individuelles, les promesses de performance globales de Nvidia ne sont pas aussi extrêmes. Tout compte fait, la société promet une augmentation des performances 6x contre Pascal, et cela ne spécifie pas par rapport aux pièces. Le temps nous dira si même cela est une évaluation réaliste, car même avec les cœurs RT, le tracé des rayons en général est toujours tout à fait le porc de ressource.
Quant aux questions de jeu en particulier, les avantages du rendu hybride sont potentiellement significatifs, mais cela dépendra fortement de la façon dont les développeurs choisissent de l’utiliser. Du point de vue des performances, je ne suis pas sûr qu’il y ait beaucoup à dire ici, et c’est parce que le tracé des rayons et le rendu hybride sont finalement des fonctionnalités pour améliorer la qualité du rendu, et non améliorer les performances des algorithmes d’aujourd’hui. Certes, si vous essayiez de faire des rayons de rayon sur les GPU d’aujourd’hui, ce serait extrêmement lent – et Turing une accélération incroyable en conséquence – mais personne n’utilise des systèmes de traçage de chemin lent sur le matériel actuel pour cette raison. Le rendu hybride consiste donc plutôt à remplacer les approximations et les hacks de la technologie de rasterisation actuelle par des méthodes de rendu plus précises. En d’autres termes, moins de «truquer» et plus de «faire.”

Ces avantages de qualité, à leur tour, sont généralement regroupés autour de l’éclairage, des ombres et des réflexions. Les trois fonctionnalités sont intrinsèquement basées sur les propriétés de la lumière, qui, en termes simplistes, se déplacent en tant que rayon, et qui jusqu’à présent divers algorithmes ont simulé le travail impliqué ou des scènes de «pré-cuisson» à l’avance. Et bien que les algorithmes actuels soient assez bons, ils ne sont toujours pas proches de précis. Il y a donc une place claire pour l’amélioration.


Nvidia pour leur part, jette particulièrement l’illumination mondiale, qui est l’une des tâches les plus difficiles. Cependant, il existe également d’autres méthodes d’éclairage qui en bénéficient, sans parler des réflexions et des ombres de ces objets allumés. Et à vrai dire, c’est là que les mots sont un mauvais outil; Il est difficile de décrire à quel point une ombre tracée par rayon est meilleure qu’une fausse ombre avec PCSS, ou un éclairage en temps réel sur un éclairage précoé. C’est pourquoi Nvidia, la société de cartes vidéo, va pousser les aspects visuels de tout cela plus dur que jamais.
Dans l’ensemble, le rendu hybride est la caractéristique Lynchpin de la série GeForce RTX 20. Selon leurs présentations Gamescom et Siggraph, il est clair que Nvidia a beaucoup investi dans le domaine et qu’ils ont parié le succès de la marque GeForce au cours des années à venir sur cette technologie. Les noyaux RT et les noyaux de tenseur sont un matériel de fonction semi-fixe; Ils ne peuvent pas être utilisés pour la rasterisation, et les transistors qui leur sont alloués sont des transistors qui auraient pu être dédiés à plus de matériel de rasterisation autrement. Nvidia a donc fait une décision incroyablement significative ici en termes de coût d’opportunité en parcourant la route de rendu hybride plutôt que de construire une plus grande Pascal.
En conséquence, Nvidia tente un changement de paradigme dans le rendu des consommateurs, celle que nous ne voyons vraiment qu’avec l’introduction de pixels et de vertex (DX8 & DX9 ERA Tech) en 2001 et 2002. C’est pourquoi l’initiative DirectX Raytracing (DXR) de Microsoft est si importante, tout comme les autres initiatives de développeur et de consommation de Nvidia. Nvidia doit vendre des consommateurs et des développeurs sur cette vision du mélange de rasumrisation avec le traçage des rayons pour offrir une meilleure qualité d’image. Et plus que cela, ils doivent faciliter les développeurs dans l’idée de travailler avec des unités de fonctions fixes plus spécialisées alors que la loi de Moore continue de ralentir et le matériel de fonction fixe devient un moyen d’atteindre une plus grande efficacité.
Nvidia n’a pas parié la ferme sur le rendu hybride, mais ils n’ont jamais tenté de déplacer le marché de cette façon. Donc, s’il semble que Nvidia est hyper concentré sur le rendu hybride et le traçage des rayons, c’est parce qu’ils sont. C’est leur vision de l’avenir, et maintenant ils doivent faire participer tout le monde à bord.
Turing SM: noyaux INT dédiés, cache unifié, ombrage variable
Aux côtés des noyaux RT et du tenseur dédiés, le multiprocesseur en streaming de Turing (SM) apprend également de nouvelles astuces. En particulier ici, il hérite de l’un des changements les plus nouveaux de Volta, qui a vu les noyaux entiers séparés en leurs propres blocs, au lieu d’être une facette du point flottant Cuda Core. L’avantage ici – au moins autant que nous l’avons vu à Volta – est qu’il accélère la génération d’adresse et les performances de multiplisation de multiplier (FMA), mais comme avec beaucoup d’aspects de Turing, il y a probablement plus (et ce qu’il peut être utilisé pour) que nous ne voyons aujourd’hui.
Le SM Turing comprend également ce que Nvidia appelle une «architecture de cache unifiée.”Comme j’attends toujours des diagrammes SM officiels de Nvidia, il n’est pas clair si c’est le même type d’unification que nous avons vu avec Volta – où le cache L1 a été fusionné avec une mémoire partagée – ou si Nvidia est allé plus loin plus loin plus loin. En tout cas, Nvidia dit qu’elle offre deux fois la bande passante de la «génération précédente», ce qui n’est pas clair si Nvidia signifie Pascal ou Volta (ce dernier étant plus probable).
Enfin, également caché dans le communiqué de presse Siggraph Turing est la mention de la prise en charge de l’ombrage à taux variable. Il s’agit d’une technique de rendu graphique relativement jeune et à venir sur laquelle il y a des informations limitées (en particulier sur la façon dont Nvidia la met en œuvre). Mais à un niveau très élevé, il ressemble à la prochaine génération de technologie d’ombrage multi-séries de Nvidia, qui permet aux développeurs de rendre différents domaines d’un écran à diverses résolutions efficaces, afin de concentrer la qualité (et le temps de rendu) dans les domaines où c’est le plus bénéfique.
Nourrir la bête: support GDDR6
Comme la mémoire utilisée par les GPU est développée par des sociétés externes, il n’y a pas de gros secrets ici. Les Jedec et ses 3 grands membres Samsung, SK Hynix et Micron ont tous développé la mémoire GDDR6 en tant que successeur de GDDR5 et GDDR5X, et Nvidia HA a confirmé que Turing le soutiendra. Selon le fabricant, le GDDR6 de première génération est généralement promu comme offrant jusqu’à 16 Gbit / s par broche de bande passante de mémoire, qui est 2x celui des cartes GDDR5 de la fin de la fin de NVIDIA, et 40% plus rapidement que les cartes GDDR5X les plus récentes de NVIDIA.
| GPU Memory Math: GDDR6 VS. HBM2 VS. Gddr5x | ||||||||
| Nvidia geforce rtx 2080 ti (GDDR6) | Nvidia geforce rtx 2080 (GDDR6) | Nvidia Titan V (HBM2) | Nvidia titan xp | Nvidia geforce gtx 1080 ti | Nvidia geforce gtx 1080 | |||
| Capacité totale | 11 Go | 8 Go | 12 Go | 12 Go | 11 Go | 8 Go | ||
| B / w par broche | 14 Go / s | 1.7 Go / s | 11.4 Gbps | 11 Gbps | ||||
| Capacité de puce | 1 Go (8 Go) | 4 Go (32 Go) | 1 Go (8 Go) | |||||
| Non. Chips / KGSDS | 11 | 8 | 3 | 12 | 11 | 8 | ||
| B / w par puce / pile | 56 Go / s | 217.6 Go / s | 45.6 Go / s | 44 Go / s | ||||
| Largeur de bus | 352 bits | 256 bits | 3092 bits | 384 bits | 352 bits | 256 bits | ||
| Total b / b | 616 Go / s | 448 Go / s | 652.8 Go / s | 547.7 Go / s | 484 Go / s | 352 Go / s | ||
| Tension dram | 1.35 V | 1.2 V (?) | 1.35 V | |||||
Par rapport à GDDR5X, GDDR6 n’est pas aussi grand que certaines générations de mémoire passées, car de nombreuses innovations de GDDR6 étaient déjà cuites dans GDDR5X. Néanmoins, aux côtés de HBM2 pour les cas d’utilisation très haut de gamme, il devrait devenir la mémoire de la colonne vertébrale de l’industrie GPU. Les modifications principales ici incluent des tensions de fonctionnement inférieures (1.35v), et en interne, la mémoire est désormais divisée en deux canaux de mémoire par puce. Pour une puce de large 32 bits standard, cela signifie une paire de canaux de mémoire 16 bits, pour un total de 16 canaux de ce type sur une carte 256 bits. Bien que cela signifie à son tour qu’il existe un très grand nombre de canaux, les GPU sont également bien positionnés pour en profiter car ils sont des dispositifs massivement parallèles pour commencer.

Nvidia pour leur part a confirmé que les premières cartes GeForce RTX exécuteront leur GDDR6 à 14 Gbit / s, ce qui se trouve être la note de vitesse la plus rapide offerte par tous les membres Big 3. Nous savons que NVIDIA utilise exclusivement GDDR6 de Samsung pour leurs cartes quadro RTX – vraisemblablement parce qu’elles ont besoin de la densité – cependant pour les cartes GeForce RTX, le champ devrait être ouvert à tous les fabricants de mémoire. Bien qu’à long terme, cela laisse deux avenues ouvertes aux cartes de capacité supérieure: passant à des jetons de densité de 16 Go, soit en passant par les puces de 8 Go qu’ils utilisent maintenant.
Cotes et fins: nvlink sli, virtuallink et 8k hevc
Bien que cela n’ait pas été mentionné dans la présentation de Gamescom de Nvidia lui-même, le site Web de la série GeForce 20 de Nvidia confirme que SLI sera à nouveau disponible pour certaines cartes GeForce RTX haut de gamme. Plus précisément, le RTX 2080 TI et RTX 2080 prendront en charge SLI. Pendant ce temps, le RTX 2070 ne soutiendra pas SLI; Ceci étant un départ par rapport au 1070 qui l’a offert.
Cependant, l’aspect le plus important de cette nouvelle est que l’interconnexion cohérente du cache de NVIDIA, NVLink, arrivera sur les cartes de consommation. Les cartes GeForce GTX implémenteront SLI sur NVLink, avec 2 canaux NVLink exécutés entre chaque carte. À une bande passante combinée de 50 Go / secon. Ceci est au-dessus des autres avantages de la fonctionnalité de NVLink, en particulier la cohérence du cache. Et tout cela arrive à un moment important, car les exigences de bande passante inter-GPU continuent de monter à chaque génération.

Maintenant, la grande question est de savoir si cela inversera le déclin continu de SLI, et pour le moment je prends une approche quelque peu pessimiste, mais j’ai hâte d’entendre plus de Nvidia. 50 Go / sec est une grande amélioration par rapport à HB-SLI, mais ce n’est toujours qu’une fraction des 448 Go / sec (ou plus) de la bande passante de mémoire locale disponible pour un GPU. Donc, il ne résout pas les problèmes qui ont un rendu multi-GPU obstiné, soit avec une synchronisation AFR ou une division efficace de la charge de travail. À cet égard, il est probable que Nvidia ne prenne pas en charge nvlink sli sur le RTX 2070.
Pendant ce temps, les joueurs quelque chose de nouveau à attendre pour VR, avec l’ajout d’un support virtuallink. Le mode alternatif USB Type-C a été annoncé le mois dernier et prend en charge 15W + de puissance, 10 Gbit / s de USB 3.1 Gen 2 Données et 4 voies de vidéo DisplayPort HBR3 partout dans un seul câble. En d’autres termes, c’est un DisplayPort 1.4 Connexion avec des données supplémentaires et une puissance destinées à permettre à une carte vidéo de conduire directement un casque VR. La norme est soutenue par Nvidia, AMD, Oculus, Valve et Microsoft, donc les cartes GeForce RTX seront la première de ce que nous attendons sera finalement un certain nombre de produits prenant en charge la norme.
| Modes alternatifs USB Type-C | ||||||
| Virtuallin | DisplayPort (4 voies) | DisplayPort (2 voies) | Base USB-C | |||
| Bande passante vidéo (brut) | 32.4Gbps | 32.4Gbps | 16.2 Gbit / s | N / A | ||
| USB 3.x bande passante de données | 10 Gbit / s | N / A | 10 Gbit / s | 10 Gops + 10 Gops | ||
| Paires de voies à grande vitesse | 6 | 4 | ||||
| Maximum d’énergie | Obligatoire: 15W Facultatif: 27W | Facultatif: jusqu’à 100W | ||||
Enfin, alors que Nvidia n’a abordé que brièvement le sujet, nous savons que leur bloc d’encodeur vidéo, NVENC, a été mis à jour pour Turing. La dernière itération de NVENC ajoute spécifiquement la prise en charge du codage HEVC 8K. Pendant ce temps, Nvidia a également été en mesure de régler davantage la qualité de leur encodeur, leur permettant d’obtenir une qualité similaire qu’auparavant avec un débit vidéo de 25% plus bas.